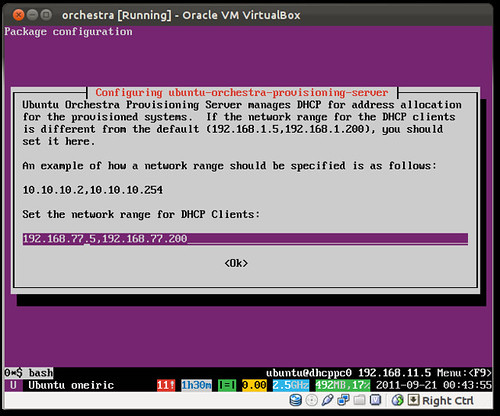
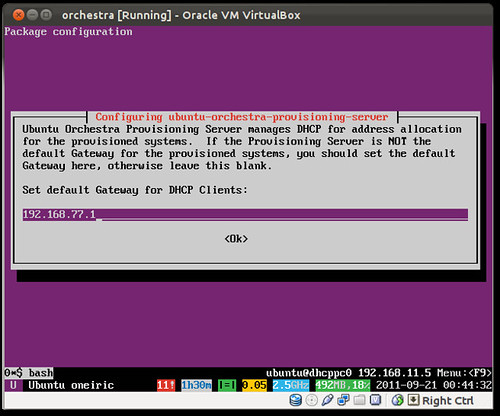
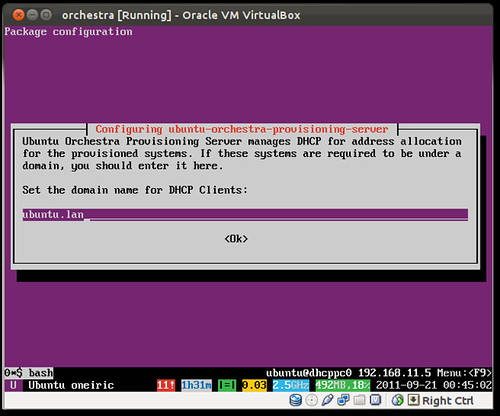
First, let's check where we are. You see installing the orchestra server, it automatically downloads and imports various Ubuntu server ISOs and creates all the needed structure (distros, profiles ...etc) in the underlying cobbler system. Let's see what have we
$ sudo cobbler list distros: hardy-i386 hardy-x86_64 lucid-i386 lucid-x86_64 maverick-i386 maverick-x86_64 natty-i386 natty-x86_64 oneiric-i386 oneiric-x86_64 profiles: hardy-i386 hardy-i386-juju hardy-x86_64 hardy-x86_64-juju lucid-i386 lucid-i386-juju lucid-x86_64 lucid-x86_64-juju maverick-i386 maverick-i386-juju maverick-x86_64 maverick-x86_64-juju natty-i386 natty-i386-juju natty-x86_64 natty-x86_64-juju oneiric-i386 oneiric-i386-juju oneiric-x86_64 oneiric-x86_64-juju systems: repos: hardy-i386 hardy-i386-security hardy-x86_64 hardy-x86_64-security lucid-i386 lucid-i386-security lucid-x86_64 lucid-x86_64-security maverick-i386 maverick-i386-security maverick-x86_64 maverick-x86_64-security natty-i386 natty-i386-security natty-x86_64 natty-x86_64-security oneiric-i386 oneiric-i386-security oneiric-x86_64 oneiric-x86_64-security images: mgmtclasses: orchestra-juju-acquired orchestra-juju-availablewoah! that sure makes my life easier. If you're interested to see where the isos were downloaded (like I was) here you are
ls /var/lib/cobbler/isos/ hardy-i386-mini.iso lucid-i386-mini.iso maverick-i386-mini.iso natty-i386-mini.iso oneiric-i386-mini.iso hardy-x86_64-mini.iso lucid-x86_64-mini.iso maverick-x86_64-mini.iso natty-x86_64-mini.iso oneiric-x86_64-mini.iso
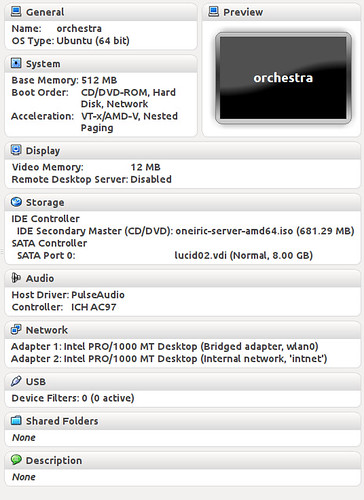
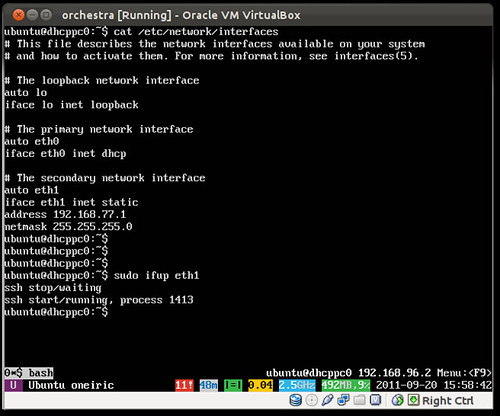
Let's create a new virtual box VM, to serve as our new "server" that needs to be installed. Here's how it looks for me
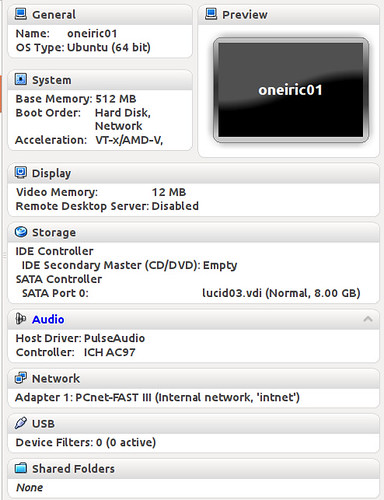
One thing is worth noting however, it's that the NIC is placed on the "intnet" network, which has the IP range 192.168.77.0/24 that we configured in the first part of this article
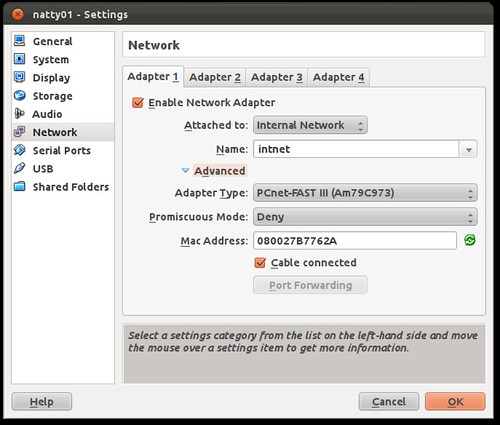
now the only "real" thing you have to do, is to add a profile on the orchestra server for your new bare server. The profile binds its mac address, to a name and an installation profile (think OS to install, kickstart ..etc)
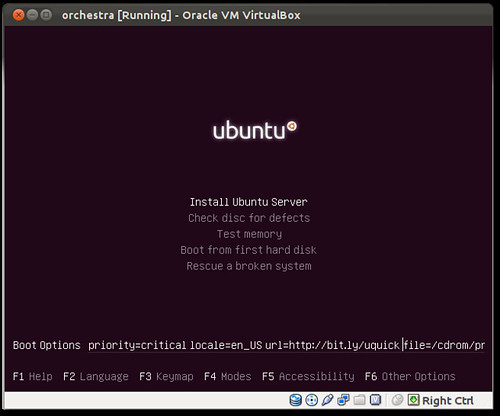
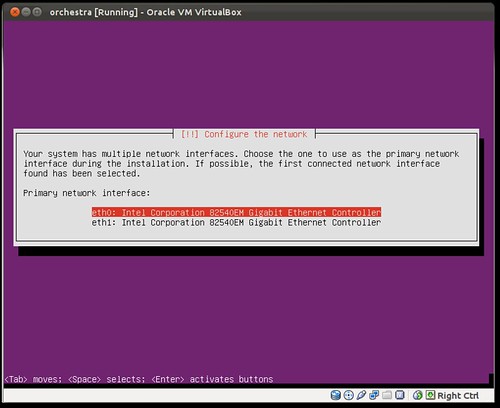
sudo cobbler system add --name="oneiric01.ubuntu.lan" --mac-address="08:00:27:B7:76:2A" --ip-address="192.168.77.33" --dns-name="oneiric01.ubuntu.lan" --hostname="oneiric01.ubuntu.lan" --profile="oneiric-x86_64-juju" --mgmt-classes="orchestra-juju-available" --kopts=" DEBCONF_DEBUG=developer netcfg/dhcp_timeout=120 netcfg/choose_interface=eth0"Boot the server, choose PXE (For vbox that's F12 then "l" that's an L)
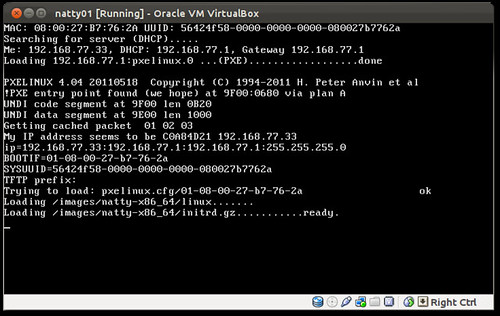
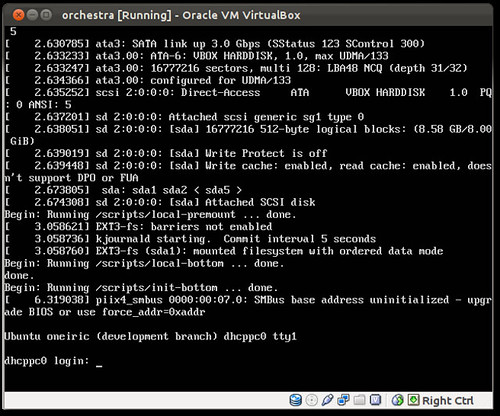
Watch the installer fly by (look ma hands free)
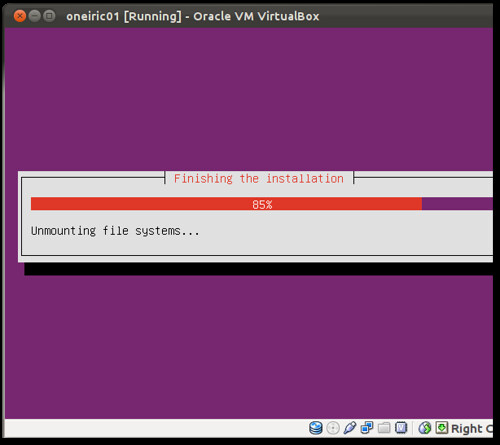
and your box is ready!
That's how easy it is to install a fresh server off your orchestra box! So basically the only thing you need to do per server, is to attach it to a profile and that's it. Boot it and it installs whatever you provisioned for it. Of course any good admin already did that manually before, but it took effort and it wasn't standardized. Now you can count on Ubuntu server covering your back when you're tasked with installing a hundred servers
How cool was that! Got thoughts, comments or rotten tomatoes ? Shoot me a comment